GLOSSARY HADOOP
Source: https://hadoopabcd.wordpress.com/glossary/
Glossary
3Vs of BigData
Three Vs of Big Data: Volume (Big), Velocity (Fast) and Variety (Smart)
More clearly define, Big Data is typically explained via 3Vs – Volume (2.5 Quintillion Bytes of data are estimated to be created every day), Variety (data from all possible source from structured to unstructured) and Velocity (tremendous speed of generating data due to increasing digitization of society).

ACID Properties
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. In the context of databases, a single logical operation on the data is called a transaction. For example, a transfer of funds from one bank account to another, even involving multiple changes such as debiting one account and crediting another, is a single transaction.
Atomicity
Atomicity requires that each transaction be “all or nothing“: if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors, and crashes.
Consistency
The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, i.e. which demands that the data must meet all validation rules including constraints,cascades, triggers, and any combination thereof.
Isolation
The isolation property ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e., one after the other. Providing isolation is the main goal of concurrency control. Depending on concurrency control method (i.e. if it uses strict – as opposed to relaxed – serializability), the effects of an incomplete transaction might not even be visible to another transaction.
Durability
Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the results need to be stored permanently (even if the database crashes immediately thereafter). To defend against power loss, transactions (or their effects) must be recorded in a non-volatile memory.
Active NN
The Active NameNode is responsible for all client operations in the cluster. Only one active NameNode could be present in a cluster.
Big ‘O’ notation
Big ‘O’ notation is a way to express the speed of algorithms.
O(1) notation means that, no matter how much data, it will execute in constant time.
O(n) notation means it takes an amount of time linear with the size of the data set, so increase the data set size double will take double the time.
O(n) notation means it takes an amount of time linear with the size of the data set, so increase the data set size double will take double the time.
CAP theorem
The CAP theorem, also known as Brewer’s theorem, states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees:
- Consistency – all nodes always give the same result.
- Availability – a guarantee that nodes always answer queries and accept updated. System is always on, no downtime.
- Partition tolerance – system continues working even if one or more nodes become silent or not responsive.
A distributed system can satisfy any two of the above guarantees at the same time but not all three.
But I am confused that how a system can give atomic consistency and perfect availability without partition tolerance in a distributed system. We cannot, however, choose both consistency and availability in a distributed system.
As a thought experiment, imagine a distributed system which keeps track of a single piece of data using three nodes—
A, B, and C—and which claims to be both consistent and available in the face of network partitions. Misfortune strikes, and that system is partitioned into two components: {A,B} and {C}. In this state, a write request arrives at node C to update the single piece of data.
That node only has two options:
- Accept the write, knowing that neither
AnorBwill know about this new data until the partition heals. - Refuse the write, knowing that the client might not be able to contact
AorBuntil the partition heals.
You either choose availability (option #1) or you choose consistency (option #2). You cannot choose both.
To claim to do so is claiming either that the system operates on a single node (and is therefore not distributed) or that an update applied to a node in one component of a network partition will also be applied to another node in a different partition component magically.
This is, as you might imagine, rarely true.
So the answer is, Consistency, Availability, and Partition Tolerance are the Platonic ideals of a distributed system–we can partake of them enough to meet business requirements, but the nature of reality is such that there will always be compromises.
Checkpointing
Checkpointing is a process that takes an fsimage and edit log and packed them into a new fsimage. This way, instead of replaying a potentially unbounded edit log, the NameNode can load the final in-memory state directly from the fsimage. This is a far more efficient operation and reduces NameNode startup time. Checkpointing is a very I/O and network intensive operation and can be time taken operation. So, rather than pausing the active NameNode to perform a checkpoint operation, HDFS defers this job to either the SecondaryNameNode or Standby NameNode depending HA configuration.

Checkpointing creates a new fsimage from an old fsimage and edit log.
Checkpointing process is triggered by one of two conditions: if enough time has elapsed since the last checkpoint (
dfs.namenode.checkpoint.period), or if enough new edit log transactions have accumulated (dfs.namenode.checkpoint.txns). The checkpointing node periodically checks if either of these conditions are met (dfs.namenode.checkpoint.check.period), and if so, kicks off the checkpointing process.Circular Buffer
A circular buffer, also known as a circular queue or ring buffer, is a high performance, first in, first out (FIFO) queue. As with any other type of queue, values can be added to the end of the queue and extracted from the start, so that items are dequeued in the same order that they were enqueued.
In some queue structures, when items are added or removed, the contents of the queue are physically moved in memory. With a circular buffer the positions are fixed. The head and tail of the queue are identified using two pointers that are updated when items are added or removed. In addition, the buffer spaces can be thought of as cyclic. After the last space in the buffer is used, the next item enqueued is stored in the first space. The diagram below shows a conceptual model of a circular buffer.

The diagram represents a circular buffer with sixteen spaces, thirteen of which are in use. In this case, the values one to thirteen have been added in order. The head of the queue is pointing at the latest value, thirteen, and the tail is at the space containing the number one. When the next item is enqueued it will be added in the next available empty space after the thirteen and the head pointer will be shifted to point to this position. When the next dequeue operation takes place the number one at the tail pointer will be extracted and the tail will move clockwise one space. When dequeuing there is no need to clear the old buffer space as the value will be overwritten at some point in the future.
Cluster
Cluster is a group of computers and other resources connected together in such a way that they behave like a single computer. Clustering is used for parallel processing, load balancing and fault tolerance. See figure
Cluster Split Brain
Split-brain can occur due to private communication fail between nodes but publiccommunication still serving client requests in which case the cluster becomes partitioned into subclusters, and each subcluster believes that it is the only partition in the cluster and promote one of the node as master and serving client request independently. In this scenario, there would be two or more master nodes and try to access a shared resource independently which could cause a conflict in shared resources as data corruption. In hadoop, when communication fail between two name nodes (active and standby) and each think that is the only node present in the cluster and standby name node promote itself to active name node, which both think they are active and try to write shared edit log. See figure1, figure2
Cluster Amnesia
An example is a two-node cluster with nodes A and B. If node A goes down, the configuration data in the cluster is updated on node B only, and not node A. If node B goes down at a later time, and if node A is rebooted, node A will be running with old contents of the cluster. This state is called amnesia and might lead to running a cluster with old configuration information.
Cluster Quorum
Quorum is a voting algorithm used to prevent split-brain (split into two or more active subclusters or partitions) problem in a cluster by assign each node one vote and mandating a majority of votes for an operational cluster. A partition with the majority of votes has a quorum and is enabled to operate and other partition will become inactive. Quorum consists of a simple majority (number of nodes / 2 + 1 extra). It is recommended to make odd number of nodes in a cluster to make a quorum otherwise in case of even number of nodes, we may need to tiebreak (if equal number of nodes in each partition) – maybe by giving a member a “super vote” or by disabling one member’s vote.
Cluster Fencing
Fencing is the process of isolating a node of a computer cluster or protecting shared resources when a node appears to be malfunctioning.
DataNode (DN)
DataNodes (DN) stores the actual Data in HDFS.
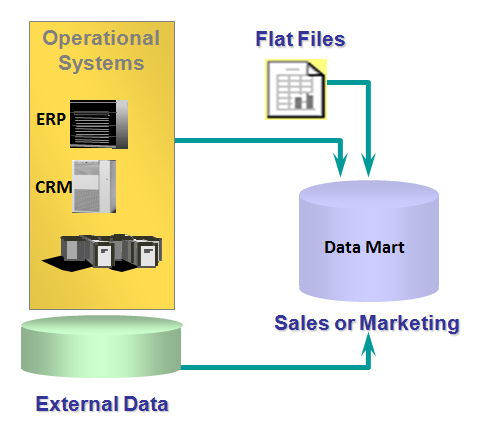
Data Warehouse vs Data Mart
A data warehouse is the place where all the data of a company is stored. It contains data from all the departments of the company. Often, it is called a central or enterprise data warehouse. Typically, a data warehouse assembles data from multiple source systems (RDBMS/CRM/ERP etc). Data can be model using Star Dataor Snowflake schema.
A data mart provides the primary access to the data stored in the data warehouse. A data mart is a simple form of a data warehouse (mini data warehouse) or subset of a data warehouse that supports the requirements of a particular department or business function, such as Sales, Finance, or Marketing. Data can be model using Star Data or Snowflake schema.
Figure shows dependent data mart: data mart exists with data warehouse

Figure shows independent data mart: data mart exists without data warehouse
Data Cleansing
Data cleaning, also called data cleansing or scrubbing, deals with detecting and removing errors and inconsistencies from data in order to improve the quality of data. E.g., due to misspellings during data entry, missing information or other invalid data. When multiple data sources (probability that some of the sources contain “dirty data” is high) need to be integrated in Data Warehouses, the need for data cleaning increases significantly. In Data Warehouses, data cleaning is a major part of the so-called ETL process. Furthermore, data warehouses are used for decision making, so that the correctness of their data is vital to avoid wrong conclusions. Examples of such invalid/inconsistent data are showing in below tables.


DDL & DML
Data Definition Language (DDL) statements are used to build and modify the tables and other objects in the database. Some examples:
- CREATE – to create objects in the database
- ALTER – alters the structure of the database
- DROP – delete objects from the database
- TRUNCATE – remove all records from a table, including all spaces allocated for the records are removed
- COMMENT – add comments to the data dictionary
- RENAME – rename an object
Data Manipulation Language (DML) statements are used to retrieve, store, modify, delete, insert and update data in the database. Some examples:
- SELECT – retrieve data from the a database
- INSERT – insert data into a table
- UPDATE – updates existing data within a table
- DELETE – deletes all records from a table, the space for the records remain
- MERGE – UPSERT operation (insert or update)
- CALL – call a PL/SQL or Java subprogram
- EXPLAIN PLAN – explain access path to data
- LOCK TABLE – control concurrency
Deadlock
A simple example is when Process 1 has obtained an exclusive lock on Resource A, and Process 2 has obtained an exclusive lock on Resource B. If Process 1 then tries to lock Resource B, it will have to wait for Process 2 to release it. But if Process 2 then tries to lock Resource A, both processes will wait forever for each other.
Namespace
It consists of files, directories, file blocks etc. Namespace operations are creation of files, deletion of files, renaming of files etc.
DFS Namespaces
A namespace is a logical layer that is inserted between clients (users and applications) and file systems. A DFS (Distributed File System) namespace is basically a place where you will have links to all your file shares. As it means an administrator can use a namespace to logically arrange and present data to users, irrespective of where the data is physically located. Your users will see it as a single share with many folders and they will have no idea that they are navigating across a set of servers to get to the subfolders and files.

ETL (Extract-Transform-Load)
Most Data Warehouse systems are front-ended with an ETL system. The purpose of this system is to:
- Extract data from outside source systems to a staging area.
- Transform it to fit operational needs with business calculations applied.
- Load it from the staging area into the target data warehouse.
Popular ETL tools are DataStage, Informatica, or SQL Server Integration Services (SSIS).
File Edit Log
A file edit log (transaction log or operations log) tracks changes to the namespace of a file system. A file edit log will record changes such as creates, links, unlinks (deletions), renamed files, data changes, and metadata changes which can be applied to fsimage file through checkpointing process.

Filesystem Metadata
Filesystem Metadata is the data that describes the structure of a file system, such as hierarchical namespace, file and directory attributes and mapping of file to data chunks.
roughly, 1 GB metadata = 1 PB physical storage
HA Cluster
The HDFS High Availability (HA) feature addresses the below problems by providing the option of running two redundant NameNodes in the same cluster in
an Active/Passive configuration with a hot standby. This allows a fast failover to a new NameNode in the case that a machine crashes.
an Active/Passive configuration with a hot standby. This allows a fast failover to a new NameNode in the case that a machine crashes.
1. In the case of an unplanned event such as a machine crash, the cluster would be unavailable until an operator manually restarted the NameNode.
2. Planned maintenance events such as software or hardware upgrades on the NameNode machine would result in periods of cluster downtime.
2. Planned maintenance events such as software or hardware upgrades on the NameNode machine would result in periods of cluster downtime.
Hadoop Daemon
Daemons in computing terms is a process that runs in the background. Under Windows such process are called service. In Hadoop, each of the daemon run in its own JVM.
Hadoop Distributed File System (HDFS)
HDFS is a distributed, highly fault-tolerant file system designed to run on low-cost commodity hardware. HDFS stores file system metadata and application data separately. HDFS architecture consists of NameNode, DataNode, and HDFS Client. NameNode stores file system metadata and DataNode stores actual application data. HDFS client always first communicate with NameNode and then it will directly communicate with DataNode for any read and write operation on actual data.

HDFS Client
Client program developed in Java or other language, which writes and reads files to and from hadoop cluster. User applications access the filesystem using the HDFS client, a library that exports the HDFS filesystem interface.
Internet of Things (IoT)
Simply put this is the concept of basically connecting any device with an on and off switch to the Internet (and/or to each other). This includes everything from cell phones, coffee makers, washing machines, headphones, lamps, wearable devices and almost anything else you can think of. This also applies to components of machines, for example a jet engine of an airplane or the drill of an oil rig. As I mentioned, if it has an on and off switch then chances are it can be a part of the IoT. The analyst firm Gartner says that by 2020 there will be over 26 billion connected devices…that’s a lot of connections (some even estimate this number to be much higher, over 100 billion). The IoT is a giant network of connected “things” (which also includes people). The relationship will be between people-people, people-things, and things-things.
How does this impact you?
The new rule for the future is going to be, “anything that can be connected, will be connected.” But why on earth would you want so many connected devices talking to each other? There are many examples for what this might look like or what the potential value might be. Say for example you are on your way to a meeting, your car could have access to your calendar and already know the best route to take, if the traffic is heavy your car might send a text to the other party notifying them that you will be late. What if your alarm clock wakes up you at 6 am and then notifies your coffee maker to start brewing coffee for you? What if your office equipment knew when it was running low on supplies and automatically re-ordered more? What if the wearable device you used in the workplace could tell you when and where you were most active and productive and shared that information with other devices that you used while working?
Join
INNER JOIN – This produces a set of records which match in both the user (id, name, course) left table and course (id, name) right table, i.e. all users who are enrolled on a course:
SELECT user.name, course.name
FROM `user`
INNER JOIN `course` on user.course = course.id;
OUTER JOIN – This produces all the records from both left and right tables whether they match or not. It fill with NULL value if it does not match.
LEFT JOIN – This produces all the records from left side table whether they match or not. It fill with NULL value if it does not match.
RIGHT JOIN – This produces all the records from right side table whether they match or not. It fill with NULL value if it does not match.
Log Processing
There is a large amount of “log” data generated at any sizeable internet company. This data typically includes (1) user activity events corresponding to logins, page views, clicks, “likes”, sharing, comments, and search queries; (2) operational metrics such as service call stack, call latency, errors, and system metrics such as CPU, memory, network, or disk utilization on each machine.
OLTP vs OLAP
We can divide IT systems into transactional (OLTP) and analytical (OLAP). In general we can assume that OLTP systems provide source data to data warehouses, whereas OLAP systems help to analyze it.
OLTP (On-line Transaction Processing) deals with operational/transactional data and is designed to efficiently process short high volumes of transactions (INSERT, UPDATE, and DELETE). The main emphasis for OLTP systems is put on very fast query processing, maintaining data integrity in multi-access environments and an effectiveness measured by number of transactions per second. In OLTP database there is detailed and current data, and schema used to store transactional databases is the entity model (usually 3NF). Example of OLTP systems are Operational Systems (RDBMS/ERP/CRM etc).
OLAP (On-line Analitical Processing) deals with historical data and is designed for analysis and decision support. It is characterized by relatively low volume of transactions. In addition, the Queries needed for these systems are often very complex and involve aggregations as for OLAP systems the response time is an effectiveness measure. In OLAP database there is aggregated, historical data, stored in multi-dimensional schemas (usually star/snowflake schema). Example of OLAP system are Data Warehouse Systems (Teradata/Hadoop).
Page Cache
If data is written, it is first written to the Page Cache (in an area of memory) and managed as one of its dirty pages. Dirty means that the data is stored in the Page
Cache, but needs to be written to the underlying storage device first. The content of these dirty pages is periodically transferred (the flusher threads then periodically write back to disk any dirty pages) to the underlying storage device.
Cache, but needs to be written to the underlying storage device first. The content of these dirty pages is periodically transferred (the flusher threads then periodically write back to disk any dirty pages) to the underlying storage device.
During a page I/O operation, such as read(), the kernel checks whether the data resides in the page cache. If the data is in the page cache, the kernel can quickly return the requested page rather than read the data off the disk.
MapReduce
Distributed huge data batch processing framework written in Java.
MD5 Hash
MD5 which stands for Message Digest algorithm 5 is a widely used cryptographic hash function. The idea behind this algorithm is to take up input data (.txt/.zip/.tar or binary) and generate a fixed size “hash value” (e.g. e4d9 09c2 90d0 fb1c a068 ffad df22 cbd0) as the output. The input data can be of any size or length, but the output “hash value” size is always fixed (32 digit hexadecimal value).
Whenever you download any valuable data from the Internet, it is completely necessary that you check the integrity of the downloaded file. That is, you need to ensure that the downloaded file is exactly the same as that of the original one. The file can be corrupted due to any of the following reasons:
- Data loss during the download process, due to instability in the Internet connection/server.
- The file can be tampered due to virus infections or
- Due to Hacker attacks.
In this scenario, the MD5 hash can become handy. All you have to do is generate MD5 hash (or MD5 check-sum) for the intended file on your server. After you download the file onto your PC, again generate MD5 hash for the downloaded file. Compare these two hash values and if they match, that means the file is downloaded perfectly without any data loss. Otherwise it means that the file is corrupt.
You can even try this on your own using the MD5 hash generator tool here.
NameNode (NN)
NameNode stores meta data (No of Blocks, On Which Rack which DataNode the actual data is stored and other details) about the actual data being stored in HDFS. Sometimes it is called Metadata Server.
Namespace Vs Metadata
The NameNode manages the filesystem namespace. It maintains the filesystem tree and the metadata for all the files and directories in the tree. Essentially, Namespace means a container. In this context is means the file name grouping or hierarchy structure.
Metadata contains things like the owners of files, file permission, no of blocks, block locations, size etc.
NAS
Network Attached Storage (NAS) is a single shared storage device which is a convenient and centralised place to store and share data among multiple computers in a network. See figure
NFS
Network File System (NFS) is a distributed file system protocol , allowing a user to access files over a network much like local storage (hard drive) is accessed. For example, if you were using a computer linked to a second computer via NFS, you could access files on the second computer as if they resided in a directory on the first computer.
Node
Any system (computer) or device connected to a network is called a node.
On-Line Transaction Processing (OLTP)
On-Line Transaction Processing (OLTP) databases are designed for large numbers of concurrent transactions, where each transaction is a relatively simple operation processing a small amount of data.
Persistence data structure
Immutable (does not allow modification) data structure with history. No in-place modification. Operations on it create new data versions.Older versions are always available. Making update to a persistent data structure instance always creates a new instance that contains this update. We want persistence data structures to be space and time efficient. Two of most popular persistence data structure are Btree and Queue.
Figure: History of updates

Persistence queue

Represent a queue using two lists:
- the “front part” of the queue
- the “back part” of the queue in reverse order
E.g.:
([1,2,3],[7,6,5,4]) represents the queue with elements 1,2,3,4,5,6,7
To enqueue (Write operation) an element, just cons it onto the back list.
To dequeue (Read operation) an element, just remove it from the front list.
To dequeue (Read operation) an element, just remove it from the front list.
So, there is no inter-dependency between the writes and reads, and they can occur simultaneously.
Rack
Rack is a standardized frame to hold collection of network equipments (switches, routers, UTM appliances, servers, patch panels, cables, modems, etc). See figure
Race Condition
A race condition occurs when two threads access a shared variable at the same time and they try to change it at the same time. Because the thread scheduling algorithm can swap between threads at any time, you don’t know the order in which the threads will attempt to access the shared data. Therefore, the result of the change in data is dependent on the thread scheduling algorithm, i.e. both threads are “racing” to access/change the data.
“Real-time” mean
Real-time is often used to describe two different ideas:
- Data “freshness” – how much time has passed since the data was written into the database until we can include it in analytics results?. Terms that fit this quick analytical access to the data are real-time (immediate), near real-time (within seconds), low latency (minutes) or high latency (hours).
- Query response time – how long does it take before the user receives a response – the classic “how quick is the query” question. Terms that fit here are immediate (real-time event response), interactive/ad-hoc (seconds), “quick” (minutes) and batch (hours).
Ad-hoc query example: An Ad-hoc Query is a query which is created on the fly, it’s not predefined. As the basic structure of an SQL statement consist of SELECT keywordFROM table WHERE conditions, an ad hoc query dynamically supplies the keyword, data source and the conditions without the user knowing it.
UseCase-1: Stock trading – uses real-time data that is fresh, and requires an immediate response time.
UseCase-2: Dashboards – are typically near real-time, and requires an immediate response time. If you’ve invested time and money to create a dashboard, you’d want it to show what was going on minutes ago, not yesterday.
SAN
Storage Area Network (SAN) is a high-speed collection (pool) of shared storage devices interconnected through Fibre Channel like LAN. See figure
Secondary NameNode (SNN)
SNN is a checkpoint node which stores the image of primary NameNode at certain checkpoint and is used as backup to restore NameNode.
Standby NN
The Standby NameNode is simply acting as a slave, maintaining enough state to provide a fast failover if necessary.
Stream Data
A stream is a continuous flow of data. Ex. A video is a stream of still images.
Stream Processing
Stream processing refer to a method of continuous computation that happens as data is flowing through the system. A real time processing system can be achieved by using a software architecture that utilizes continuous (stream) processing. In stream processing, sometimes data might be awaiting processing. The only constraint on such a stream processing system is that its output rate (consumtion) should be faster or atleast equal to the input rate (producing). Otherwise the storage requirements of the system grow without bound. Additionally, it must have enough memory to store queued inputs should it be stuck while processing any item in the input stream.
Switch
A switch is a computer networking device that connects devices together on a computer network. Each rack of nodes is interconnected using a rack-level switch. Each rack-level switch is connected to a cluster-level switch. See figure
Tuple
The tuple is the main data structure in Storm. A tuple is a named list of values, where each value can be any type.
Zero Copy
Applications which take data copy from disk to socket require multiple copies of same data. So it not only consumes CPU cycles and memory bandwidth, also I/O performance is going down. Fortunately, you can eliminate these copies through a technique called — zero copy.
Traditional Approach: Copying bytes from a file to a socket

Zero-Copy Approach: Copying bytes from a file to a socket

This category contains courses related to Hadoop
|
||
Navigation:
|
|
***
GRADE-8
SEGMENT-I
GRADE-8
SEGMENT-II
******
5 thoughts on “Glossary”